MCP + RAG で知識を取得して出力するAgentを試す
LM Studioでベクターストアに知識を入れて、MCP呼び出しで知識を取得する様子を試しています
記事作成日:2025-12-05, 著者: Hi6
概要
下記の実験後にRAGに言語やフレームワークのドキュメントを詰めて、投げられたクエリに対する言語のドキュメント知識を返すMCPを構築し、LM Studio から ”AstroのAdapter API について説明して” のような質問をすると、AgentがMCPを呼び出しAstroに関する情報を取得しそれをもとに最終出力を生成するところを確認する。
- [[LangChain ベクターストアへのデータの保存]]
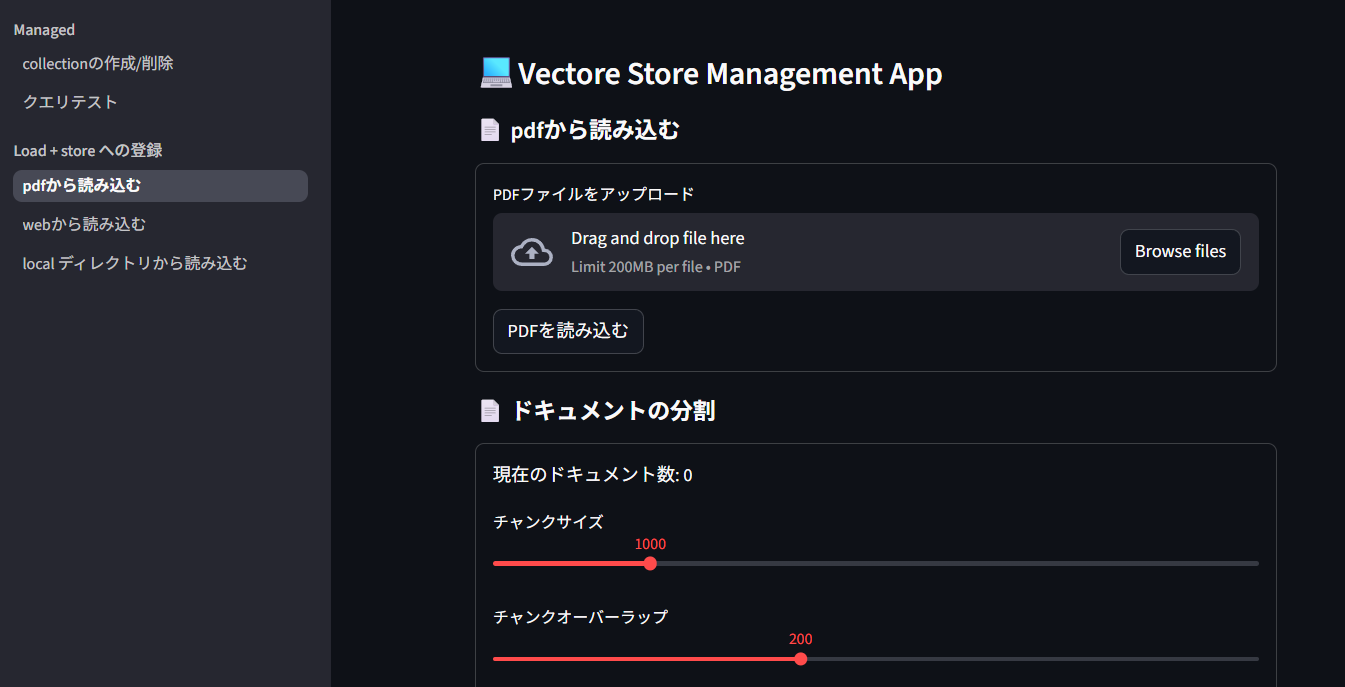
- ベクターストアへの保存は上記実験を参考にstreamlitなどを利用しで一連の流れを行うアプリを作成しておくと後々が便利です。
- [[LangGraph エージェントのツール呼び出しを確認する]]
- [[MCP FastMCPでサーバーとクライアントを試す]]
MCP サーバーの構築
ドキュメントから情報を取得するMCPサーバーをFast MPCで構築します。embeddingはローカルのOLLAMAに置いた、日本語に対応している granite-embedding:278m を利用し、ベクターストアにはsqliteベースのChromaを使用しています。
from fastmcp import FastMCP
from langchain_community.vectorstores import Chroma
from langchain_ollama import OllamaEmbeddings
OLLAMA_HOST = "http://127.0.0.1:11434"
PERSIST_DIRECTORY = "./chroma_langchain_db" # この中に chroma.sqlite3が入ります
EMBEDDING_FUNCTION = OllamaEmbeddings(\
model="granite-embedding:278m", base_url=OLLAMA_HOST)
tool_result_num = 3 # 類似検索語に検索結果をいくつ取得するかの設定
mcp = FastMCP("Flaps MCP Server", mask_error_details=True)
vector_store_js = Chroma(
collection_name="javascript_collection",
persist_directory=PERSIST_DIRECTORY,
embedding_function=EMBEDDING_FUNCTION
)
vector_store_astro = Chroma(
collection_name="astro_collection",
persist_directory=PERSIST_DIRECTORY,
embedding_function=EMBEDDING_FUNCTION
)
# ツールの定義
@mcp.tool
def javascript_context(query: str):
"""javascriptに関するクエリに答えるための情報を取得してください。"""
retrieved_docs = vector_store_js.similarity_search(\
query, k=tool_result_num)
serialized = "\n\n".join(
(f"Source: {doc.metadata}\nContent: {doc.page_content}") \
for doc in retrieved_docs
)
return serialized
@mcp.tool
def astro_context(query: str):
"""Astroに関するクエリに答えるための情報を取得してください。"""
retrieved_docs = vector_store_astro.similarity_search(\
query, k=tool_result_num)
serialized = "\n\n".join(
(f"Source: {doc.metadata}\nContent: {doc.page_content}") \
for doc in retrieved_docs
)
return serialized
if __name__ == "__main__":
mcp.run(transport="http", host="127.0.0.1",port=8081)LM Studio から生成を試す
生成モデルがMCPを呼び出すには、モデルがツール呼び出しに対応したモデルを選択する必要があります。

この青いマークがついているものがツールを呼び出せるLLMです。ちなみに黄色いほうは画像を認識できるモデルです。今回は上記、mistralで試します。
LM StudioにMCPを登録する作業が必要です。
右の install タブから edit mcp.json を選択し MCPサーバーのアドレスを json ファイルに登録します。
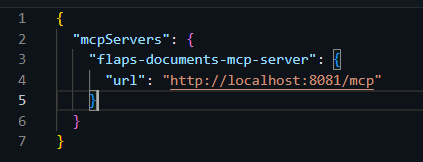
そうすると右にMCPサーバーが立ち上がっていれば、登録したサーバーが表示され選択できるようになるのでチェックを入れて有効化します。ちなみに・・・いろいろとドキュメントを入れてあります・・・・
次にシステムプロンプトを書いてこういった場合にはMCPツールを呼び出してドキュメントを取得してくださいとの指示を出しておきます。
あなたは、プログラミング、ソフト開発に精通した優秀なAiアシスタントです。ユーザーの質問に対し下記のツールを使用して関連ドキュメントを取得してください。
- javascriptに関する質問はツールの javascript_context を使用。
- Astroに関する質問はツールの astro_context を使用。あとは、プロンプトを投げてみるだけです。
”AstroのAdapter API について説明して”
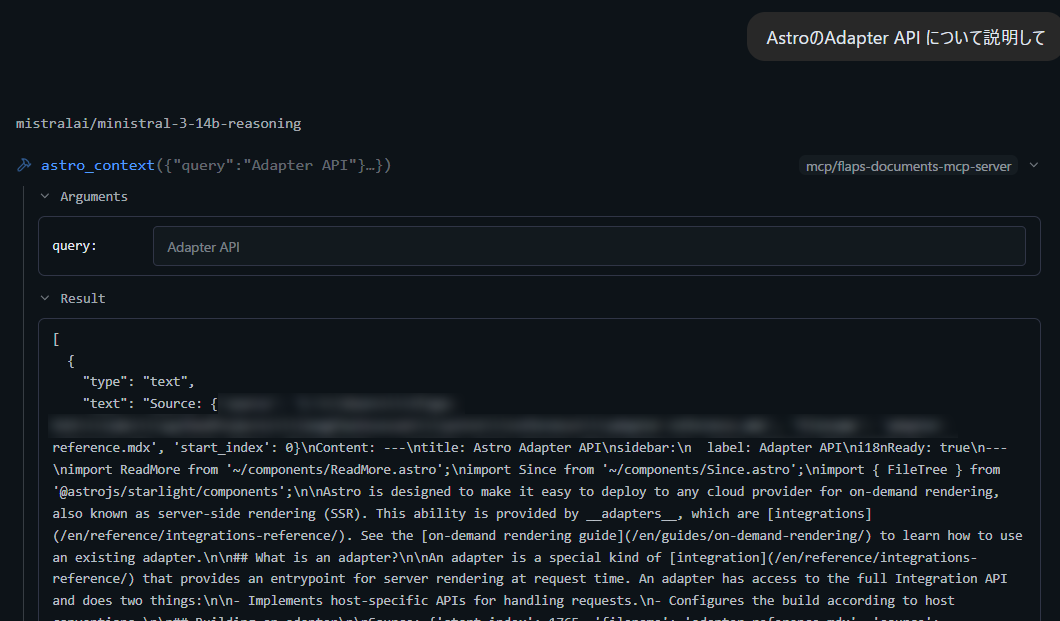
MistralがMCP astro_context に対して {"query": "Adapter API"} を投げてドキュメントを取得している様子がうかがえます。この部分を表示するには、たしか・・設定の中でチャットにデバッグ情報ブロックを表示にチェックを入れてやる必要があったと思います。
簡単な質問に対してはドキュメントを取得して、それをもとに回答を出力しますが・・・少し複雑な質問、例えば https://docs.astro.build/ja/reference/adapter-reference/
Astro の Adapter API における app.removeBase()はAstroのバージョンいくつで追加されたかドキュメントを取得して確認してなどの情報は取得できていない・・・投げたクエリーを見てみると下記のようなクエリを投げています。このクエリでは情報は取得できないでしょう・・・内容が絞り込めていない・・・
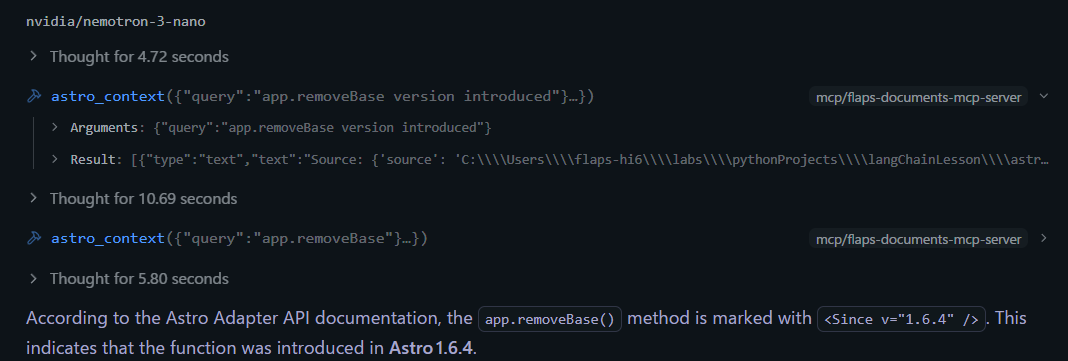
Astro の Adapter API における app.removeBase() はどのバージョンで追加されたかここで深く考えられるモデルに変更して再度試してみます。

緑のマークが深く思考できるタイプのモデルです。上記nvidia/nemotron-3-nanoで再度同じ質問を試してみました。そうすると繰り返しクエリーを投げ適切な回答が得られるまで試行を繰り返している様子が伺え、結果として正しいバージョンを教えてくれました。